说明
阅读本文章需要具备一定K8S基础知识,如果你还不了解这些,建议先看看这里
什么是CSI
CSI是Container Storage Interface的简称,旨在能为容器编排引擎和存储系统间建立一套标准的存储调用接口,通过该接口能为容器编排引擎提供存储服务。
K8S支持CSI标准的诞生背景
在CSI之前,K8S里提供存储服务是通过一种称为“in-tree”的方式来提供,这种方式需要将存储提供者的代码逻辑放到K8S的代码库中运行,调用引擎与插件间属于强耦合,这种方式会带来一些问题:
- 存储插件需要一同随K8S发布。
- K8S社区需要对存储插件的测试、维护负责。
- 存储插件的问题有可能会影响K8S部件正常运行。
- 存储插件享有K8S部件同等的特权存在安全隐患。
- 存储插件开发者必须遵循K8S社区的规则开发代码。
当前已有的FlexVolume机制试图通过调用一个可执行的程序包方式去解决这些问题,虽然它已经能够做到让存储提供方进行独立开发,但是有两个问题还没有得到很好解决,1. 在部署这些可执行文件时,需要host的root权限,依然存在安全隐患。2. 存储插件在执行mount、attach这类操作时,往往需要到host去安装第三方工具或者加载一些依赖库,这样host的OS版本往往需要定制,不再是一个简单的linux发型版本,这样的情况太多,会使部署变得复杂。例如:ceph需要安装rbd,gluster mount需要安装mount.glusterfs等等。
基于此,就需要K8S支持CSI标准。支持这套标准以后,K8S和存储提供者之间将彻底解耦,终极目标是将存储的所有的部件作为sidecar container运行在K8S上(当前设计还没有完全做到,需要一个兼容的发展周期),而不再作为K8S部件运行在host上。换句化说未来K8S项目将聚焦在面向应用的容器集群管理上,存储将外置由vendor自己维护。
K8S CSI插件实现
设计概述
正如上节讲到,CSI的出现的初衷是要解决上诉问题的,FlexVolume已经解决了部分问题,所以K8S 支持CSI并没有对现有的存储机制做大的调整,主要核心思想是保留了当前 K8S存储架构, 将CSI作为一个类似于FlexVolume的插件插入到当前的K8S系统中提供存储服务,结构如下图:
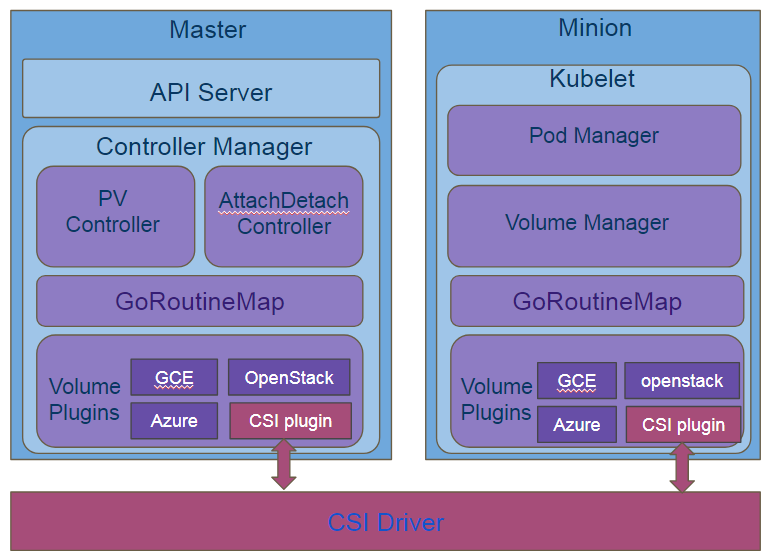
大致看上去,这个和FlexVolume并没有太大的变化,其实不然,FlexVolume中Plugin和driver之间的调用使用的是操作系统命令行接口,而CSI采用的是grpc调用,grpc调用的一个优势就是可以将grpc服务运行在socket上,这样服务端就可以运行在socket端点的任何地方,换句话说就是可以被隔离,即运行在容器里(熟悉docker的同学是否能看到熟悉的设计思路?),解决了上述提到的Flexvolume没有解决掉的两个问题。接下来详细看下如何解决这两个问题的。
设计详述
如前K8S存储架构介绍,K8S中卷的管理的核心就6个流程:provision/delete, attach/detach, mount/unmount。flexvolume作为外置存储的plugin,核心实现了后4个流程,provision/delete则由vendor通过自己开发外置的provisioner的方式提供支持,不属于flexvolume。对于CSI plugin也就类似,唯一不同的是K8S提供一个sidecar容器来运行这个外置的provisioner。注意这里的容器和上一段提到的容器是两个不同容器,换句说这里将有两个容器,官方建议的部署逻辑图如下:
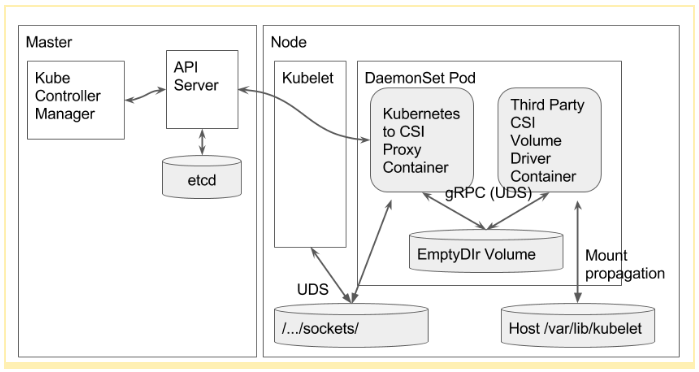
在这6个流程中,其中mount/umount, 在kubelet中触发相应操作后由CSI plugin调用CSI driver(由厂商自己提供的CSI接口实现,类似于flexvolume的driver)做相应的mount/umount操作;provision/delete操作由外置controller通过监听API-Server,做相应的创卷、删卷操作并更新API中实体状态。这四个流程并没有大的变化,唯一的区别就是将flexvolume的driver调用方式改为了grpc,调用接口标准化为CSI了。
其中变化最大的是attach/detach逻辑,要理解这里的变化,除了了解顶级流程(参见K8S存储架构)外,需要对其中的AD Controller有深入的理解。注:对于Kubelet端的attach/detach流程是作为mount/unmount的前置步骤,流程是嵌入在mount/unmount中的,只会是调用,不会涉及大的变化,所以这里就直接略过了,想了解详情和看下这段代码
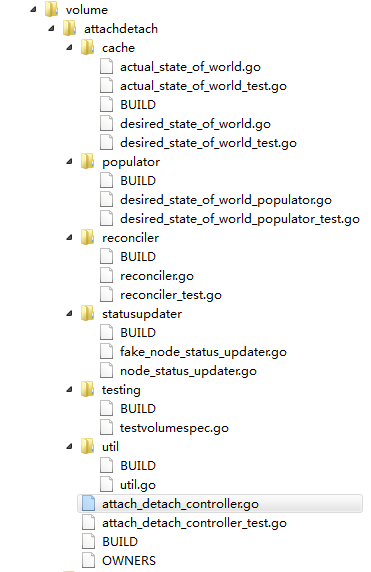
AD Controller中核心部件包括两个缓存,一个populator,一个reconciler,一个status updater。
- 两个缓存分别是desired status和actual status,分别代表跟attach/detach相关对象模型的期望状态和实际状态。
- reconciler通过定期比较期望状态和实际状态来决定是执行attach,还是detach,还是什么都不做。
- populator负责定期从API Server同步相关模型值到期望状态缓存中。
- status updater负责node的状态刷新,这里主要是当有卷做完attach/detach操作后,从记录实际状态缓存中获取每个node已经attach的卷信息,向API Server同步node.Status.VolumesAttached,通过这个状态Kubelet才知道AD Controller是否已经完成attach操作。详细代码查看这里,结构见下图:
核心的逻辑部件有一定了解之后,再梳理下它的逻辑。对于AD Controller来讲,它的核心职责就是当API Server中,有卷声明的pod与node间的关系发生变化时,需要决定是通过调用存储插件将这个pod关联的卷attach到对应node的主机(或者虚拟机)上,还是将卷从node上detach掉,这里的关系变化可能是pod调度某个node上,也可能是某个pod在node上终止掉了,所以它需要做这几件事情:
- 监控API Server 中的pod和node。
- 监控当前各个node上卷的实际attach状态。
- 通过对比API Server中pod和node的状态变化以及node上的实际attach状态来决定做attach、detach操作。
- 调用相应的卷插件执行attach,detach操作。
- 操作完成后,通知其它关联组件(这里主要是kubelet)做相应的业务操作。
了解了这个业务流程和相应内部部件职责后,剩下的就是读代码看细节了,这里就不做详细的介绍了,代码路径,如有疑问,欢迎交流。
回到CSI设计上来,对于AD Controller来讲,当reconciler检测要做相应的attach或者detach操作时,是直接通过调用volume plugin来实现,K8S存储架构 提到AD Controller是运行Master节点上,而在K8S里Master节点原则上是不运行容器的,那么将CSI Driver移植到容器里运行后,AD Controller调用CSI Driver就将变成跨节点调用,如果通过网络socket直接调用讲存在两个问题:1. 因为CSI Driver外置后,对于K8S进程来讲它其实是一个不可信逻辑单元,远程调用安全如何保证。2. 调用端如何确定,节点间直接调用也打破了K8S的逻辑架构。
而对于K8S设计来讲,Master执行完一段逻辑后触发Minion做相应的逻辑的设计太普遍,都是通过API Server内部接口更新状态的方式来设计,如前面提到的AD Controller执行完attach操作后通过node.Status.VolumesAttached通知Kubelet做mount操作。这里K8S CSI也沿用了这个设计方案。即AD Controller通过向API Server写入一个对象,在Minion侧开启一个进程监听这类对象变化,当检测了有对象Add则执行attach操作,有对象delete则执行detach操作,具体参数则通过这个内部对象属性传递给Minion。于是就引入了两个变化:
- 定义一个用于attach/detach的内部API对象
- 增加一个attach/detach的Minion代理,负责监听1中定义的对象变化,再调用本节点上CSI driver执行相应的操作。 于是就有了图2中右边部分的CSI Proxy Container,剩下的就是考虑这些部件间的通信机制打通。
对于常规的非容器化方案,CSI Plugin运行在K8S核心部件里,CSI Plugin与CSI Driver之间通过grpc调用。K8S各部件间通过API Server进行通信,CSI Plugin如同K8S的核心部件拥有host上root权限,也不需要额外的通道处理,这种模式对于通信机制没有特殊诉求。
但正如一开始所说,为解决当前的问题,存储容器化是必然,所以将CSI运行在容器里是必然选择,如图2,运行在容器里,整个上诉提到的部件,主要有K8S的三个核心部件,API-Server,Controller Manager(AD Controller,PV Controller),Kubelet。CSI引入了两个容器,一个是CSI Proxy Container,一个是CSI Driver Container,他们的通信方式如下图:
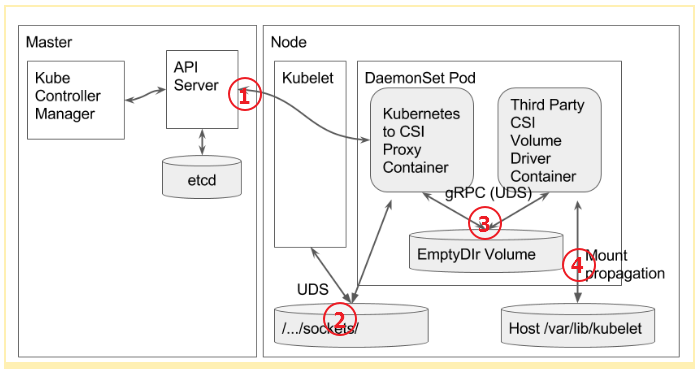
- Controller Manager与CSI Driver之间通过API Server通信来进行卷的attach/detach操作.
- Kubelet与CSI Proxy Container之间通过本地socket通信。
- CSI Proxy Container 与CSI Driver Container之间通过本地socket通信。
- 由于CSI Driver Container需要在Host上做Mount操作,所以需要将操作目录作为卷提供给Container。
这样这个流程也就能正常运转了,核心的设计已经介绍完,最后以几个图的形式来将三个核心流程呈现一下:
- provision/delete
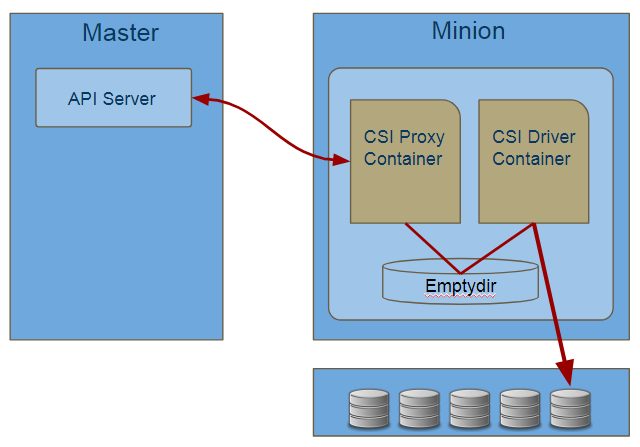
CSI proxy通过监听API Server有PVC的Add/Delete操作后通过host与container的socket调用CSI接口,CSI Driver接收到调用后,调用存储设备实现卷的增删。
- attach/detach
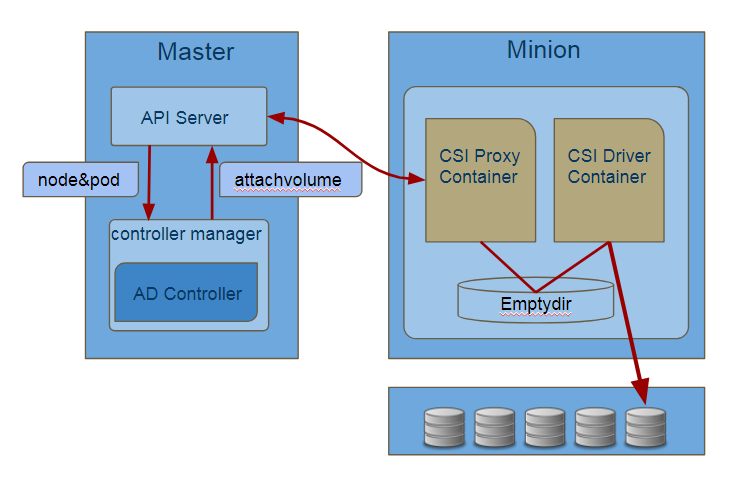
AD Controller监听API Server的pod,node状态判断是否进行attach/detach操作,如果需要进行,CSI Plugin则通过API Server创建/删除attachvolume(内部API对象). CSI Proxy Container中的attacher监听到API Server中attachvolume的增删后,通过本地socket调用另一个容器中的CSI Driver执行attach/detach操作(注意,CSI接口不是这个名称),CSI Driver再通过调用存储后端完成attach/detach操作。操作完成后,CSI Proxy Container更新attachvolume状态。
- mount/unmount
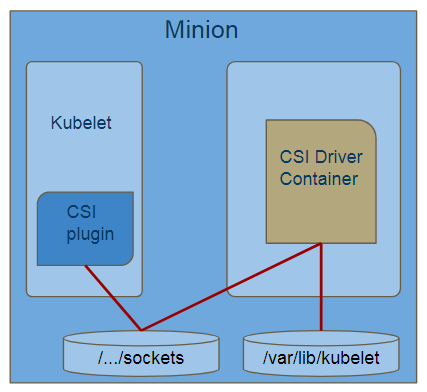
Kubelet判断需要做mount操作,通过Host到container的socket调用CSI Driver,CSI Driver在容器内部通过挂载到容器里的Mount Point卷进行bind mount操作。
总结
整体来看K8S CSI的设计与Flexvolume没有大的出入,整体架构保持不变,唯一差异较大的就是attach/detach流程。但正如一开始提到的,K8S后续将聚焦在容器集群支持应用上,存储应该整体外置,K8S目前为了兼容已有的存储架构,将attach/detach做得相对复杂了,如果是没有包袱的厂商,完全没有必要做这么复杂的一套设计,可以提前将存储相关的控制器外置到容器里,简化这么复杂的通信机制,只需提供一个机制告诉Kubelet存储ready即可。